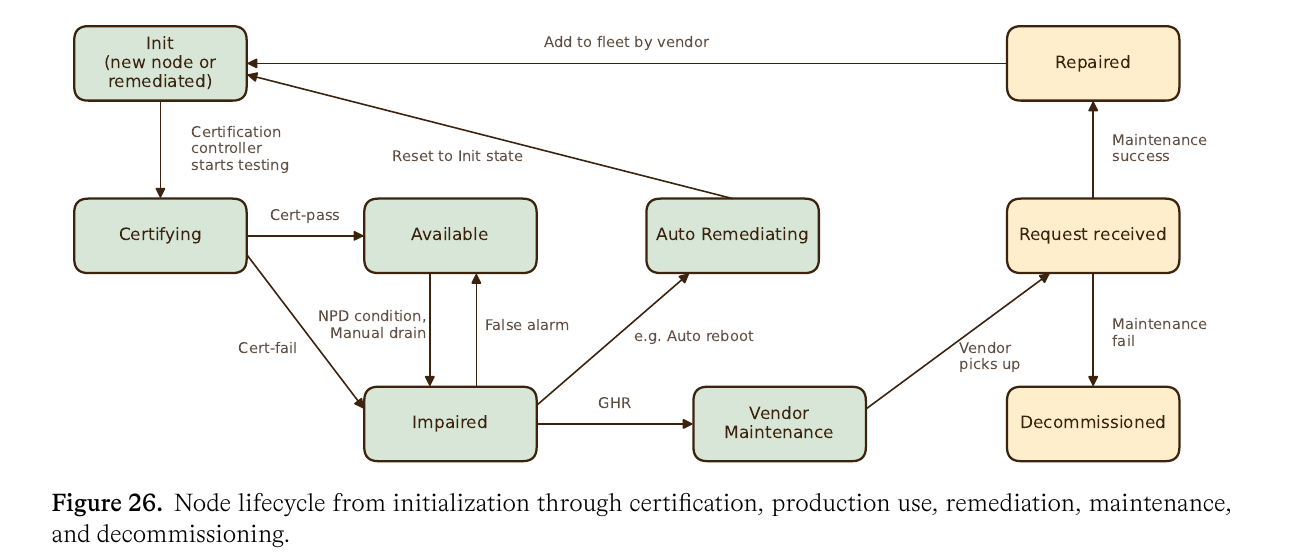
后训练 RL:从 Trainer 框架到 Runtime 系统
导读
核心观点
后训练 RL 的竞争点正在从 换哪种训练目标(objective) 迁移到 能否稳定组织一条可观测、可回放、可扩展的训练链路。
本文结构与要点
全文围绕五条主线展开:系统视角、Runtime 系统、框架坐标、补充展开与落地选型。
| 篇章 | 章节 |
|---|---|
| 系统视角 | 核心变化、Reward、KL、数据 |
| Runtime 系统 | Runtime 角色、服务与调度、吞吐瓶颈、OPD 服务化 |
| 框架坐标 | 框架对比、社区路标 |
| 补充展开 | Objective 演进、Agentic RL、稳定性、系统扩展 |
| 落地 | 四层分工、框架选型、结论 |
除 objective 外,框架还需组织 rollout、reward、环境、serving、trace 回流与故障恢复。各部分核心论点如下:
系统视角
- 后训练 RL 已从算法问题变成系统工程问题
- 优化对象从单轮回答扩展到真实任务过程
- Reward 是系统接口,不仅是单标量分数
- KL 只能约束分布距离,无法约束任务语义
- RL 数据是动态轨迹资产,不是静态 dataset
Runtime 系统
- RL 框架正在从 trainer 变成 runtime
- RL 系统走向服务化与调度化,因为 trainer 抽象不够
- 生产态推理集群可作为低优先级 rollout 后端,而非简单混入线上请求路径
- OPD 将 teacher feedback 变成需要调度、观测和回放的高成本服务
- 大规模后训练的瓶颈常常在 rollout
框架坐标
- 框架按调度层、训练栈、代码谱系等维度分类
- 另有研究向、轻量实验、零侵入 Agent、fork 衍生等补充类别
- 社区路标集中在 multi-turn、async、tool、production
补充展开
- Objective / feedback 路线从 PPO、GRPO 扩展到 OPD
- Agentic RL 放大 credit assignment、token 对齐与稳定性问题
- 系统扩展规律从单点吞吐转向 loop goodput(有效吞吐)
落地
- 未来系统会分成应用、环境、编排、模型 runtime 四层
- 框架选型应围绕当前瓶颈做检查
- 竞争壁垒在训练链路,不在单个 trainer repo
文中会反复提到 DPO、GRPO、OPD 等方法名;各 objective / feedback 路线的形式对照见后训练 Objective 速查。
系统视角:从算法到系统工程
核心变化:从 RLHF 到 Agentic RL
观点:后训练 RL 的核心变化,不是 objective 公式突然颠覆,而是优化对象从“单轮回答偏好”扩展到了“真实任务过程”。
分析线索:对比旧 RLHF 链路与 agentic RL 训练链路。
早期 RLHF 常可概括为:
1 | SFT -> Reward Model -> PPO |
该链路仍成立,但已不足以描述当前的 post-training。更完整的流程可表示为:
1 | 任务 / 环境 / 工具 -> 轨迹采样 -> 可验证反馈 / judge / reward shaping |
对于 chat alignment,样本通常是 prompt 和 response,reward 通常反映对最终回答的整体偏好。在 agentic post-training 中,样本变为多轮轨迹:模型需读文件、调用工具、执行命令、观察结果、修正计划并提交 artifact。此时 reward 除最终回答质量外,还需覆盖过程可靠性、工具使用有效性与结果可验证性。
后训练 RL 的一个要点是:环境设计与算法选择同等重要。
弱环境配合强算法,可能导致模型 exploit reward 设计缺陷;清晰环境配合可验证信号,即便算法相对简单,也能提供稳定的优化方向。
Reward:系统接口,不仅是分数
观点:Reward 在工程实现中更接近跨系统接口,而非 trainer 直接消费的单标量。
分析线索:reward contract 要同时表达任务完成、质量、约束、过程、安全、成本与稳定性。
常见讨论将 reward 视为标量分数;在工程实现中,reward 更接近跨系统接口。
这个接口至少包含几层信息:
- 任务是否完成;
- 完成质量如何;
- 有没有违反约束;
- 过程里是否出现不可接受行为;
- 哪些子步骤值得鼓励或惩罚;
- reward 是否存在被模型 exploit 的风险;
- reward 的延迟、成本和稳定性如何。
在数学题、代码题、工具任务中,可验证 reward 可将部分主观偏好转化为客观检查:测试是否通过、命令是否成功、artifact 是否符合格式、答案是否可被程序验证。
但可验证并不等于简单。真实任务经常会出现这些问题:
- 单个最终结果可验证,但中间过程不可见;
- 测试集太窄,模型学会过拟合测试;
- judge 本身不稳定,导致 reward 噪声放大;
- reward 只关心结果,模型学会高风险路径;
- reward 过度 shaping 时,模型可能优化 shaping 信号而非任务本身。
因此 reward 设计类似 API 设计:接口语义不清时,trainer、rollout engine 与数据平台需承接由此产生的歧义与耦合。
可预期的是,post-training 团队将逐步沉淀各领域的 reward contract。coding、terminal、browser、office、search、math、data analysis 等场景各有不同的可验证条件、失败类型与 trace schema。通用 RL 框架主要提供集成接口,效果取决于具体领域 contract 的质量。
KL:分布约束,不是安全边界
观点:KL 是控制 policy drift 的手段,不是 agentic RL 的安全边界本身。
分析线索:区分 KL 能管什么,以及必须由 reward 反作弊、环境隔离、replay / eval 处理什么。
RLHF 中常见做法是通过 KL penalty 将 policy 约束在 reference model 附近,以限制 policy drift。在 PPO-RLHF 中,reward 提供优化方向,reference 与 KL 提供分布约束。
但在 agentic RL 中,KL 的作用需单独评估。
一方面,KL 仍可用于防止 policy 为短期 reward 牺牲语言质量、格式规范与基本行为边界。另一方面,agent 任务通常要求 policy 偏离 SFT 初始分布:更长规划、更主动的工具使用、更多自我修正与失败恢复。KL 过强时,policy 可能被约束在原有行为分布附近,难以学习新策略。
因此 KL 并非安全机制本身,而是控制 policy drift 的手段。稳定性还依赖:
- reference / KL;
- reward 反作弊设计;
- 环境权限隔离;
- rollout 过程审计;
- bad case replay;
- 离线 eval 与在线 shadow eval;
- 对工具、文件、网络、执行命令的边界控制。
概括而言:KL 约束分布距离,不约束任务语义。
RL 数据:动态轨迹资产
观点:RL 数据是随 policy 变化不断生成的 trajectory asset,而不是一次性准备好的静态 dataset。
分析线索:trajectory schema 至少要覆盖复现、归因和 replay 所需字段。
SFT 消费静态语料;RL 则持续生成新数据。
每轮 policy update 后,模型分布变化,下一轮 rollout 的错误类型、工具调用模式、回答长度与失败方式也随之变化。数据并非固定存储中的静态文件,而是由当前 policy 与环境交互动态产生。
这带来以下工程后果:
- 数据质量与 policy 版本强绑定;
- trace 需记录足够上下文以支持复现;
- reward 版本变化会影响跨轮比较;
- old policy / new policy / reference policy 的 logprob 须严格区分;
- 失败样本通常具有较高分析价值,可用于后续改进。
因此 RL 数据平台不宜仅按 dataset 模型设计,而更接近 experiment log、trajectory store、replay buffer 与 evaluation archive 的组合。
对框架来说,这意味着数据结构里至少要能表达:
- prompt / observation / action / response;
- token logprob;
- reward breakdown;
- judge version;
- environment version;
- tool call result;
- timeout / exception;
- policy checkpoint;
- sampling params;
- trace span。
缺少上述字段时,后续归因分析将十分困难。
Runtime 系统:从 Trainer 到 Runtime
Runtime 角色:组件与边界
观点:现在看 RL 框架,重点不是内置了几种 post-training 方法,而是能否组织一整条训练链路。
分析线索:框架抽象要同时解释 policy、reference、reward、rollout、environment、trainer、scheduler、data store、observability 的关系。
评估 RL 框架时,不应仅关注是否内置 PPO / GRPO 模块,而需评估其组织完整训练链路的能力。
一个 LLM RL 框架通常至少要处理这些角色:
| 角色 | 作用 |
|---|---|
| Policy / Actor | 被训练的模型,负责生成动作或文本 |
| Reference Model | 冻结策略,用于 KL 约束 |
| Reward / Judge | 给最终结果或过程打分 |
| Value / Critic | PPO 等 actor-critic 方法里的价值估计 |
| Rollout Engine | 高吞吐生成,通常要接 vLLM / SGLang 等推理后端 |
| Environment | 工具、浏览器、终端、代码沙箱、任务状态 |
| Trainer | 在 training batch 上计算 loss,执行 forward / backward 与参数更新 |
| Scheduler | 放置不同 worker,管理异构资源 |
| Data Store | 存轨迹、logprob、reward、checkpoint、eval 结果 |
| Observability | trace、metrics、错误归因、长尾请求分析 |
这里最关键的是 policy update 和 rollout generation 的关系。
传统深度学习训练中,DataLoader 按 batch 加载样本,trainer 执行 forward/backward,数据路径与训练路径边界较为清晰。LLM RL 中,rollout generation 本身是一个分布式推理系统,且需频繁同步最新 policy,训练系统因而成为训推混合系统。
因此许多框架强调 Ray、vLLM、colocated placement、offload、async rollout、hybrid engine、placement group 等能力。这些并非“外围工程”,而是 RL 框架的核心组成部分。
服务与调度视角:Runtime 的系统边界
图示:RL 后训练系统架构图
观点:现代 RL 后训练系统的边界正在从“计算 loss 的 trainer”扩大到“组织跨服务 data loop 的 runtime”。
分析线索:将 rollout、reward、environment、policy publish / weight sync、trajectory store、observability 视为独立服务,分析调度层如何维持 goodput 与版本语义。
这里的 goodput 指有效吞吐:不是系统总共生成了多少 token 或处理了多少请求,而是单位时间内有多少可用、可验、版本语义正确的 trajectory 最终进入 reward 与 policy update。
RL 系统正在服务化
后训练 RL 系统不再只是一个 trainer 脚本加几段 rollout 代码,而是由多个职责清晰的服务协作:
| 服务 | 职责 |
|---|---|
| Rollout Service | 高吞吐生成;接 vLLM / SGLang / Megatron inference,或直接接生产推理集群 |
| Reward / Judge Service | rule-based verifier、PRM、LLM-as-judge、测试执行 |
| Environment Service | sandbox、browser、terminal、tool calling、多轮状态 |
| Policy Publish / Weight Sync Service | job 内 rollout worker 的权重同步,或外部 serving fleet 的 policy version 发布 |
| Trajectory Store | episode、logprob、reward breakdown、env version、policy version |
| Teacher / Distillation Service | OPD 中提供 token-level logits、chunk-level feedback、multi-teacher scoring 或 verifier-gated teacher signal |
| Observability Service | trace、p99、timeout、failure taxonomy、reward drift |
这些服务之间的数据流构成 training loop:policy 更新触发权重同步或版本发布,Rollout Service 按新 policy 生成 trajectory,Environment Service 提供交互状态,Reward / Judge Service 产出可版本化的反馈,Trajectory Store 持久化全链路字段,Observability Service 将失败与长尾归因至具体环节。
核心变化是:RL 框架的边界从“计算 loss”扩大到“组织服务间的 data loop”。Rollout Service 承担 policy 的 generation forward(推理采样);Trainer 承担 policy update(通常需在已收集 batch 上重算 logprob / value,再 backward 更新权重)。
系统能否扩展,取决于各服务能否独立扩缩、版本对齐与失败隔离。
OPD 亦会在 RL 系统中引入高成本的 Teacher / Distillation Service。传统 RLVR 的瓶颈在 rollout 与 verifier;OPD 还需在学生 trajectory 上调用 teacher,并将 token / chunk / step 级反馈回传 trainer。
服务接口因此需支持 teacher model version、teacher logits 或 compressed feedback、chunk-level preference / semantic score、feedback span 与 token span 对齐、teacher-student tokenizer mapping、feedback latency / queue delay。若 rollout 使用生产态推理集群的低谷容量,OPD 进一步要求调度层同时安排 student rollout 与 teacher feedback,并隔离二者的优先级、版本和队列延迟,RL 后训练系统因而趋向 multi-model inference orchestration。
Rollout Service 是训练系统里的在线推理服务
Rollout 无法以 trainer 内单次 model.generate() 概括。其本质是面向 RL 负载的在线推理服务,具有 serving 系统的典型特征:
- batching 与 continuous batching;
- KV cache 管理与 prefix 复用;
- speculative decoding;
- 长尾请求与 straggler;
- 权重热更新 / policy version publish 与 worker health check;
- 请求超时、局部重试与 worker 故障恢复。
但它又不同于面向用户的线上 serving:优化目标不是单请求 latency,而是 RL step 的 goodput——单位 wall-clock 内有多少有效 trajectory 进入 reward 和 update。这意味着 batch 策略、截断策略、并发上限都要围绕“样本吞吐”而不是“p99 延迟 SLA”来设计。
推理后端的选择反映 workload 差异。SGLang 侧重多轮结构化执行、KV 复用与程序式 rollout;vLLM 侧重通用 serving 与生态覆盖。框架侧大致为:slime / Miles / Relax 倾向 SGLang,OpenRLHF / vime 倾向 vLLM,verl / ROLL / NeMo-RL 支持双后端。选型应基于 workload 是单轮大批量、长上下文多轮,还是工具环境驱动的 agentic generation,而非单一 benchmark 分数。
生产推理集群可能成为 rollout 后端
图示从左到右为三种演进形态:Colocated(rollout 与 trainer 同 job 部署,也称 embedded)、Disaggregated Rollout Service(为本训练任务单独部署 rollout 集群,经 queue / RPC 与 trainer 解耦)、Production Inference Rollout(训练过程中接入生产态推理平台,用低优先级 / 可抢占任务消纳低谷或弹性余量)。
后两种的数据流相近:trainer 下发 prompt,rollout 回传 trace + logprob;差别在于 2 通常是 trainer 将更新后的权重同步到训练专用 rollout worker,3 更像 trainer 将 policy version 发布到 serving 控制面,由生产态推理池按版本装载或路由。
传统 RL 框架默认 rollout engine 随训练 job 启动:训练集群同时承担 generation forward 与 policy update(forward / backward),权重在 trainer 与 rollout worker 间本地同步。该模式适用于小规模、严格 on-policy 实验;在 agentic RL / coding RL 场景中,rollout 的负载形态接近线上 agent serving——请求长、并发高、工具链复杂、长尾明显,需要成熟 serving 的 batching、调度、监控与弹性扩缩。
因此一种架构选择是:将 rollout generation 交由现有生产推理集群或 serverless inference pool 的低优先级可用容量,而非在 trainer 进程内调用 model.generate()。
以 Cursor + Fireworks 为例:Cursor 具备 coding agent 场景与大规模 trajectory 需求;Fireworks 提供生产级推理、弹性 fleet 编排、batching 与低延迟 serving。公开材料显示,Cursor 在与生产 serving 相同的基础设施上运行 RL rollout inference,并可在生产流量低谷时将容量分配给 RL、高峰时收回。
这里的关键不是把 RL 请求当作普通线上请求混入用户路径,而是让 rollout 作为低优先级 / 可抢占 workload 使用生产态推理集群的闲置容量。Fireworks 亦将 rollout inference 产品化:团队自带 trainer,使用 Fireworks 提供 rollout serving、policy publish / version pinning 与 fleet 编排。
这种路线的潜在收益:
- 复用生产 serving 已有的调度、batching、KV cache、监控、健康检查;
- rollout 容量可弹性扩缩,无需与 trainer GPU 绑定;
- 线上 trace、离线 rollout、evaluation traffic 更容易统一在一个 inference API 层;
- agent 应用侧和 RL 训练侧可以共享同一套 LLM proxy / inference gateway 能力,但通过优先级、配额、版本和租户隔离避免相互污染。
代价同样明确:
- policy 权重或版本如何快速、可靠地发布到推理集群;
- old policy / new policy / reference policy 的版本如何隔离与路由;
- logprob、token trace、sampling params 是否能完整回传,满足 on-policy / off-policy correction 需求;
- serverless / production serving 的调度目标往往是 SLA 和租户公平,而 RL 训练目标是 sample goodput,两者可能冲突;
- 网络传输、跨服务 retry 和 inference queue delay 会直接进入 training loop。
不应将生产推理理解为必然优于 colocated rollout,而是 rollout 后端可分为三类:colocated / 同 job 部署(1)、训练专用 rollout 服务(2)、生产推理平台式(3)。1 适用于严格 on-policy 与小规模实验;2 适用于需要独立扩缩但仍专属于某次训练的任务;3 适用于大规模 agentic data generation、evaluation 与近生产流量回流。
调度问题变成 RL 系统的核心能力
服务化之后,调度不再等价于“申请 N 张 GPU”。policy update、rollout generation、reward / judge、environment worker 的资源画像差异很大:
- trainer 需要 GPU 做 forward / backward(及 reference / value 等辅助 forward),对通信拓扑和 checkpoint 敏感;
- rollout 需要 GPU 做推理,对 batching 和 KV cache 敏感;
- reward 可能需要 CPU、GPU 或外部 judge API;
- environment 可能需要 CPU、容器、文件系统、网络隔离。
因此调度层要管理的是 异构 worker 的生命周期:谁启动、谁扩缩、谁与谁做 colocated placement、谁可以异步、谁失败只影响局部。
Ray 调度框架(OpenRLHF / SkyRL / AReaL / ROLL)以 Ray actor / task 组织 rollout、reward、env 等异构 worker。Relax 采用服务化异步与 TransferQueue,支持可配置 staleness。verl 以 HybridFlow 组织 train / generate / reward 节点。slime 谱系(slime / Miles / vime)采用单控制器 + Data Buffer 路径,结构相对直接;复杂 agentic workload 下的 env 编排与异步扩展可能需要额外层。
Colocated 与 Disaggregated 部署是成本和语义的 trade-off
Colocated deployment:训练与 rollout 共用 GPU,权重同步路径短,适用于小集群、同步 RL 与严格 on-policy。代价是 rollout 的 generation forward 与 trainer 的 update forward / backward 竞争 GPU 资源,长尾 generation 易产生 GPU bubble。
Disaggregated deployment:rollout / trainer / reward / env 独立扩缩,适用于大规模与 agentic RL。代价包括 staleness 上升、weight transfer / policy publish 复杂度增加、队列积压与跨服务 failure 需显式处理。Relax 的 TransferQueue、AReaL 的 fully asynchronous、DORA 的 multi-version streaming rollout 均针对 disaggregated 部署下的 goodput 与 off-policy 控制。
若 rollout 接生产推理集群,则为更彻底的 disaggregation:训练系统仅消费 API 返回的 completions、logprobs、trace 与 reward 所需元数据,不再管理 rollout worker 的本地生命周期。未来框架或将 colocated / disaggregated / production-inference rollout / async 设计为 可配置连续谱,而非二选一开关。
调度层需要显式处理 backpressure 和 staleness
Disaggregated 部署和服务化之后,training loop 的速度由最慢环节决定,而且各环节的积压会改变样本语义:
- rollout 比 update 慢:trainer 空转,GPU 利用率下降;
- rollout 比 update 快:trajectory 堆积,样本变旧,off-policy 程度上升;
- reward / judge 慢:reward 队列阻塞,rollout 完成但无法进入 update;
- environment 阻塞导致整批 rollout 等待,straggler 效应放大。
若 rollout 接生产推理集群,还将叠加 inference queue delay、rate limit、model version rollout delay、跨服务 retry 等问题。系统因此需要显式语义,而非仅扩大队列容量:
- backpressure:下游慢时上游减速或丢弃;
- timeout 与 partial retry:单条 trajectory 失败不阻塞整批;
- priority queue:eval / on-policy 样本与 backlog 样本分级;
- staleness bound 与 policy version tagging:每条样本标记生成时的 policy 版本,update 侧决定是否接受。
异步 RL 因而不仅是 --async 开关,而是 队列语义与版本语义设计。
服务化后的核心指标是 loop goodput
服务化之后,单点峰值吞吐容易误导优化方向。不应只看 trainer tokens/s 或 rollout tokens/s,更应该看 loop 指标:
- valid trajectories / hour;
- accepted reward samples / hour;
- RL step wall-clock;
- p95 / p99 rollout latency;
- timeout rate;
- judge failure rate;
- policy publish / weight transfer latency;
- stale sample ratio;
- inference queue delay;
- model version publish latency;
- recovery time after worker failure;
- teacher feedback latency;
- teacher feedback acceptance rate;
- feedback-token alignment error rate;
- teacher / verifier disagreement rate。
这些指标共同回答一个问题:单位时间内有多少有效训练样本穿过完整 loop。RL infra 的优化目标应是有效训练样本吞吐,而不是某个组件在独立基准测试里的峰值吞吐。
吞吐瓶颈:Rollout 与长尾
观点:后训练 RL 的 goodput 往往被 rollout generation 和环境长尾支配,而不是只被 backward 性能支配。
分析线索:拆解 rollout、reward / judge、policy update、checkpoint、policy publish / weight transfer 的等待关系。
后训练 RL 的成本不仅来自反向传播。对于长上下文、多轮 agent、工具调用任务,rollout 开销常超过 update。
主要原因包括:
- 自回归生成无法完全并行;
- 轨迹长度差异大,长尾请求延长 step 完成时间;
- 工具调用和环境执行会引入外部等待;
- judge / reward 可能需再次调用模型或执行程序;
- policy 变化后,推理引擎需要同步权重;
- 多轮任务会产生更长 KV cache 和更多状态。
因此 RL 框架的核心指标不应仅包含 tokens/s,还需关注:
- 每个 RL step 的 wall-clock;
- rollout 和 update 是否 overlap;
- p50 / p99 generation latency;
- straggler 对 batch 完成时间的影响;
- 失败轨迹是否能局部重试;
- 权重同步或版本发布是否阻塞;
- 环境执行是否可并发扩展。
如果 rollout 是瓶颈,那么优化 trainer kernel 可能收益有限;反而是 speculative decoding、batching、请求切分、环境并发、超时策略、异步 reward、长尾截断更重要。
框架坐标与社区路标
开源与工业路线
本节按技术特征(调度层、训练栈、代码谱系与系统架构)归纳常见开源框架。分类依据是架构与工程取向,不是维护团队或机构;同一路线中的项目可能由不同主体维护。一个框架可能同时满足多种特征(例如 Relax 与 slime / Miles / vime 同属 Megatron + SGLang 取向,但系统架构上更应归为服务化异步路线)。
| 类别 | 代表 | 训练 / rollout | 分类依据 |
|---|---|---|---|
| 实验入口 | TRL | HF Transformers | 以 HF Trainer 为入口 |
| 轻量 / 单卡 | Unsloth、LLaMA-Factory | HF + 内核优化 | 面向单机或小规模实验 |
| verl 衍生 | EasyR1、VeRL-Omni、uni-agent | verl HybridEngine + vLLM / SGLang | 继承 HybridFlow / 3D-HybridEngine |
| 可组合 dataflow | verl | FSDP / Megatron + vLLM / SGLang | dataflow graph + hybrid controller |
| Ray 调度 | OpenRLHF、SkyRL、AReaL、ROLL | Ray + Megatron / DeepSpeed + vLLM / SGLang | 以 Ray actor/task 组织异构 worker |
| slime 代码谱系 | slime、Miles、vime | Megatron + SGLang / vLLM | 继承 slime 训练栈、Data Buffer、参数透传 |
| 服务化异步 | Relax | Ray Serve + Megatron + SGLang + TransferQueue | train/rollout 独立服务 + 可配置 staleness |
| 生产 infra | NeMo-RL | Megatron + vLLM / SGLang / Megatron inference | 大规模拓扑、多模型协调、worker 隔离 |
| 早期 RLHF pipeline | DeepSpeed-Chat | DeepSpeed RLHF pipeline | SFT / reward model / RLHF 阶段化示例 |
| 零侵入 Agent | Agent Lightning、rLLM | 拦截 LLM API + verl / 自研 trainer | agent 执行与训练进程解耦 |
| 研究 / 安全 | Safe-RLHF、trlX | DeepSpeed / 自研 | 面向安全对齐等特定研究目标 |
| 未开源工业 | Forge | 自研 train / rollout / gateway | 公开材料可参照,代码未开源 |
TRL:Hugging Face 生态下的 post-training 库,支持 SFT、DPO、PPO、GRPO 等。
OpenRLHF:基于 Ray、vLLM、DeepSpeed 的 RLHF 框架,支持 PPO、DPO、KTO、GRPO 等,并提供 single-turn / multi-turn agent 模式。
verl:HybridFlow 实现,将 actor、rollout、reward、trainer 组织为可组合 dataflow,训练后端支持 FSDP / Megatron,rollout 后端支持 vLLM / SGLang。
Ray 调度:以下框架以 Ray actor / task 组织 rollout、reward、env、trainer 等异构 worker。OpenRLHF 侧重 RLHF 工程集成;SkyRL 提供 multi-turn agent RL 与异构调度,SkyRL-Agent 包含 pipeline dispatcher;AReaL 实现 generation 与 training 的 fully async 解耦;ROLL 集成 Ray、Megatron-Core、SGLang / vLLM,支持 Reinforce++、GRPO、GSPO、AutoDeviceMapping。NeMo-RL、Relax 也使用 Ray,但 NeMo-RL 主要归类为生产 infra,Relax 主要归类为服务化异步——「使用 Ray」本身不足以界定框架类别。
slime 代码谱系:以下项目继承 slime 的 Megatron 参数透传、Data Buffer 与低抽象设计,含直接 fork 或基于 slime 训练栈的再实现。slime:Megatron 训练 + SGLang rollout;Miles:slime fork,增加 FP8、R3、speculative RL、VLM multi-turn 等;vime:保留 slime 训练栈,rollout 后端改为 vLLM + vllm-router。Relax 与这一路线同样强调 Megatron + SGLang,但更适合按 Ray Serve + TransferQueue 的服务化异步路线理解。
DeepSpeed-Chat:较早的 DeepSpeed-based RLHF pipeline,将 SFT、reward model、RLHF / PPO 等阶段串成示例化流程。其定位接近早期工程参考,不宜与 modern vLLM / SGLang rollout service 或 Ray 异构调度框架等同视之。
NeMo-RL:NVIDIA 生产向 RL 框架,支持 Ray、Megatron、vLLM / SGLang、checkpoint、拓扑放置、异步 rollout、environment isolation、FP8 等。
Forge:MiniMax 内部 agent-native RL 框架(未开源)。公开材料描述三层结构:Agent Side、Middleware(Gateway + Data Pool)、Training-Inference Side(Rollout Engine + Train Engine)。支持黑盒 Agent 通过推理 gateway 接入;算法包括 CISPO、process reward、task completion time reward;工程特性包括 windowed-FIFO 调度、prefix tree merging、MTP speculative decoding、global KV cache pool。
补充分类
上一节按技术谱系列举主要 repo。以下按用途与架构模式补充几类,并说明部分共性。
工业向框架的共性:verl、OpenRLHF、slime、ROLL、NeMo-RL 等均在演进 rollout 独立部署、reward 模块化、MoE / FP8 / async 支持。差异在于调度层选型(Ray vs dataflow vs 单控制器)和训练 / rollout 后端组合。
研究向框架:Safe-RLHF 面向 helpfulness / harmlessness 约束下的 RL 对齐;trlX 曾提供 distributed RL for LLM 能力,近年维护活跃度较低。
Agent 接入的两种模式:
| 模式 | 代表 | 做法 |
|---|---|---|
| 框架内 env | Forge、OpenRLHF multi-turn、Relax BaseInteractionEnv |
在训练框架内定义 env、tool、multi-turn 交互原语 |
| 零侵入 | Agent Lightning、rLLM | 拦截 LLM API,从 agent 运行中抽取 episode / trajectory |
Agent Lightning 支持 RL、APO、SFT 等,LightningRL 将 agent 执行建模为 MDP 并做 credit assignment。rLLM 通过 @rllm.rollout 或 LiteLLM proxy 从 vLLM 获取 token id 与 logprob,训练后端为 verl 或 tinker;v0.2+ 提供 AgentWorkflowEngine,支持多 agent workflow。两种零侵入方案均需处理 agent 侧与训练侧 tokenizer / chat template 不一致带来的 logprob 与 mask 对齐问题。
轻量 / 实验向:Unsloth 提供单卡 GRPO / DPO 优化;LLaMA-Factory 支持 100+ 模型的 SFT / DPO / PPO;EasyR1 为 verl fork,面向 Qwen-VL 等多模态 GRPO、DAPO、LoRA RL。通常用于算法与 reward 验证,再迁移到 verl / slime 等大规模栈。
代码 fork 与衍生:slime 谱系的 fork(Miles、vime)共享 Megatron 参数透传与 Data Buffer,差异在 rollout 后端(SGLang / vLLM)与工程侧重(FP8 / R3、vLLM 生态)。Relax 与该谱系在 Megatron + SGLang 取向上相近,但核心差异是 Ray Serve + TransferQueue 带来的服务化异步架构。verl 谱系的 fork(EasyR1、VeRL-Omni、uni-agent)共享 HybridFlow,分别面向多模态 RL、diffusion / omni-modal、agent env 统一层。
框架可按以下维度区分定位,无单一排序标准:
| 维度 | 实验取向 | 生产取向 |
|---|---|---|
| 算法尝试 | 快速换 objective / 改 trainer | 稳定复现实验配置 |
| 资源规模 | 单机 / 小集群 | 多节点 / 千卡 |
| 生成后端 | 简单集成即可 | 权重同步、长尾、故障恢复都重要 |
| 环境复杂度 | 静态 prompt-response | 多轮 agent / sandbox / tools |
| 观测需求 | loss / reward 曲线 | trace / p99 / failure taxonomy |
| 调度需求 | 启动方便 | placement / topology / lifecycle |
选型时可按 workload 与 infra 条件匹配,而非按框架名称:
- preference optimization 实验:TRL、Unsloth、LLaMA-Factory
- 多模态 RLVR:EasyR1、VeRL-Omni
- 可扩展 RLHF:需关注生成后端、训练后端、权重同步
- 已有 vLLM infra:vime、OpenRLHF、rLLM;已有 SGLang + Megatron:slime、Miles、Relax
- agentic RL,scaffold 固定且可控:Relax、OpenRLHF、uni-agent 的内建 env
- agentic RL,scaffold 异构或黑盒:Agent Lightning、rLLM、Forge gateway(公开材料)
- 大规模 MoE:需关注拓扑、checkpoint、failure recovery
- 大规模异构 Agent scaffold:需关注 Middleware 解耦、trajectory 协议、async 调度
社区路标
观点:RL 框架分析不应仅关注当前功能列表,还需结合社区路标判断下一阶段抽象的可能收敛方向。
分析线索:持续跟踪 README news、release notes、experimental 模块、issues、meetup / tech blogs 与论文代码。
分析 RL 框架时,还需系统收集社区路标。许多项目无正式 ROADMAP.md,方向通常分散于 README news、release notes、experimental 模块、issues / discussions、meetup / tech blogs 与论文代码。
从当前社区信号看,以下主线较为清晰。
单轮 RLVR 到多轮 Agentic RL
verl 已将 multi-turn with tool calling、search tool、sandbox integration 纳入文档,experimental 方向包括 uni-agent、VeRL-Omni、fully async policy、one-step off-policy、VLA 等。
OpenRLHF README 将 single-turn agent 与 multi-turn agent 分为两种执行模式,并强调 RL algorithm 与 agent executor 解耦;multi-turn 路线包括 custom agent function、环境反馈、async pipeline 与 VLM multi-turn RL。
Forge 进一步扩展 agent executor 解耦:Agent Side 与 Train/Rollout Side 通过 Gateway + Data Pool 隔离,白盒 Agent 可将 Context Management 建模为环境状态转移,黑盒 Agent 将请求路由至 RL Gateway,由框架在推理侧采集 trajectory。MiniMax 公开材料称 M2.5 训练接入了 10 万+ 种 scaffold,multi-turn agent RL 的瓶颈正从 tool 接入能力转向异构 scaffold 的规模化接入。
Agent Lightning 与 rLLM 表明:在 episode 抽取可靠的前提下,无需预先修改 agent 代码。Agent Lightning 支持 RL、APO、SFT 等算法,Youtu-Agent 在其修改分支上验证了 128 GPU 稳定收敛;rLLM 提供 @rllm.rollout + verl 后端的 CLI-first workflow,内置 50+ benchmark。社区方向正从框架内 multi-turn env 扩展至更广泛的 agent 可训练性。
社区正在将 RLVR 从「prompt → answer → verifier」扩展为:
1 | observation -> action -> environment feedback -> next action -> final reward |
算法名称仍可沿用 GRPO / PPO / REINFORCE++,但样本形态已发生变化。
Rollout 后端服务化
Rollout 不再只是 trainer 里的一段 generate(),而是一个可以独立优化、扩容、观测和复用的系统。
OpenRLHF 已支持 async training、partial rollout、vLLM pause/resume、OpenAI-compatible agent server executor;verl 强调 vLLM / SGLang / HF Transformers 多后端及 train / generate 间的 resharding。
社区论文中亦出现 ProRL Agent 等 Rollout-as-a-Service 设计。rollout 生命周期从 trainer 中拆分 可独立优化与复用;否则多环境、多工具、多沙箱、多模型版本将使训练代码复杂度持续上升。
异步 RL:性能方向,但存在 trade-off
多个框架都在走 async:
- verl 的 experimental 里保留 fully async policy、one-step off-policy;
- OpenRLHF 支持 async RLHF / async agent RLHF,也明确提示 async queue 会带来 off-policy 程度;
- NeMo-RL 的功能列表里写了 Async RL、asynchronous rollouts、replay buffers、fully asynchronous GRPO;
- Forge 用 windowed-FIFO 在吞吐与分布一致性之间折中:窗口内允许局部乱序以消除 straggler,窗口外禁止跳读,避免训练分布被 fast sample 偏移。
为提高 goodput,社区持续将 rollout、reward、training 进行 overlap。
但异步亦引入新问题:样本可能来自旧 policy,in-flight rollout 可能混合新旧权重,advantage / KL / correction 的设计因而更为关键。async RL 因此不仅是 --async 开关,还需配套 off-policy correction、replay buffer、staleness control、partial rollout consistency 等机制。
多模态与工具环境进入主线
TRL 定位为 Hugging Face 生态的 post-training trainer 集合,覆盖 SFT、GRPO、DPO、RewardTrainer 等入口。
系统型框架正在扩展多模态与环境集成:
- verl 新闻里有 VeRL-Omni、VLM / multi-modal RL;
- OpenRLHF 0.10 增加 VLM RLHF 和 Multi-Turn VLM RL;
- NeMo-RL 支持 VLM、SGLang rollout、NeMo-Gym、multi-turn RL、environment isolation。
这意味着后训练 RL 的“环境”不再只返回文本。后续可能会出现图像 observation、浏览器截图、视频帧、GUI state、代码执行结果、数据库查询结果、文件 diff 等混合状态。
大规模生产化压过单点算法
NeMo-RL 的功能列表 / roadmap 侧重 infra:SGLang backend、speculative decoding、Yarn long-context、Megatron inference、fault tolerance / auto-scaling、MoE performance、FP8、GB200、environment / worker isolation。
Forge 的 roadmap 侧重 agent scaffold 规模化:黑盒 / 白盒 Agent 统一接入、Context Management 纳入 RL 交互环、prefix tree merging、heterogeneous PD disaggregation、global L3 KV cache pool,以及 mixed-domain(Reasoning / General QA / Agent)联合训练。工业实践中,scaffold 支持范围与内置训练目标种类同为框架能力的重要维度。
verl 也在 FSDP2、Megatron backend、LoRA RL、large MoE、AMD ROCm、SGLang unique features 上持续推进。
大规模 RL 框架的重点将继续包括:
- rollout 加速;
- 训练 / 推理权重转换或同步;
- MoE 与长上下文性能;
- 多硬件支持;
- checkpoint / fault tolerance;
- 环境和 worker 隔离;
- recipe 可复现。
社区路标可区分为算法路标与系统路标:前者关注优化方法,后者关注能否持续、低成本、稳定地完成训练。
社区原型先于主框架暴露需求
除主框架外,还需关注其生态中的衍生项目。
VerlTool 等工作在 Verl 生态中集成 tool use、异步 rollout、多模态 observation 与统一工具 API,反映 tool-augmented RL 对插件化与环境标准化的需求。
AgentRL 强调 multi-turn、multi-task、fully asynchronous generation-training pipeline、containerized environment 与 centralized controller,反映 agentic RL 在 multi-task 环境与异步流水线方面的工程压力。
MUA-RL 将 simulated user 纳入 RL loop,表明 multi-turn agent 除 tool calling 外,亦涉及动态用户意图与澄清过程。
这些项目未必都会成为最终标准,但它们能提前暴露主框架即将补的接口:tool API、environment controller、simulated user、sandbox lifecycle、multi-task normalization、cross-policy sampling、rollout service。
因此跟踪 RL 框架时,不应仅关注 release tag,可维护如下社区路标表:
| 来源 | 重点看什么 |
|---|---|
| README news / release notes | 已合入能力、即将合入能力、WIP 标记 |
| docs advanced usage | 多轮、工具、sandbox、reward、rollout 后端接口 |
| experimental 目录 | 下一批可能进入主线的抽象 |
| examples / recipes | 社区已验证的 workload |
| issues / discussions | 用户遇到的工程问题 |
| meetup / tech blogs | maintainers 对框架边界的解释 |
| 论文 + 开源代码 | 新需求最早出现的位置 |
补充展开:Objective、Agentic RL 与系统扩展
前文已从系统视角、Runtime 组件和框架坐标说明:后训练 RL 的难点不只在 objective。本章补充三条更细的逻辑链:
- objective / feedback 路线如何从 PPO、GRPO 扩展到 OPD;
- agentic RL 为什么会放大 credit assignment、token 对齐和稳定性问题;
- 这些问题如何反映到同步 / 异步、colocated / disaggregated 部署和大规模 goodput 上。
Objective 演进:从 PPO 到无 critic RLVR
PPO 的价值是给 RLHF 一个稳定的“多轮复用 rollout”机制:clip ratio、value model、entropy bonus 共同控制单步更新幅度,适合偏好模型打分的 chat alignment;但在 RLVR reasoning 场景,critic 成本和不稳定性会被放大。DPO / KTO 采用离线 preference optimization 路径,省去在线 rollout,适用于快速实验,但不直接覆盖需环境交互的 agentic RL。
GRPO 的关键转向是去掉 value model,用同一 prompt 下多条采样的组内相对 reward 做 baseline,DeepSeek-R1 证明了它可以支撑 rule-based reward 的大规模 reasoning RL。RLOO(Cohere, 2024)和 ReMax(ICML 2024)也是无 critic 路线:前者用 leave-one-out baseline,后者用 greedy baseline;和 GRPO 接近,但公开讨论较少。REINFORCE++(OpenRLHF, 2025)强调全局 batch 归一化,将问题表述为低耦合 policy gradient,但方差与样本效率压力仍存在。
DAPO 的动机是复现级工程:在 DAPO 中,decoupled clip、dynamic sampling、token-level policy gradient、overlong reward shaping 等机制旨在提高进入梯度的有效样本比例,其 Qwen2.5-32B 在 AIME 2024 达到 50 分,表明算法细节与数据过滤同等重要。
CISPO 采用不同路径:在 MiniMax-M1 中放弃 trust region 约束,改为 clip importance sampling weights,让所有 token 都参与梯度;Forge 把它继续用于长 horizon agent RL,并叠加 process reward 与 completion time reward。GSPO 再进一步把优化粒度从 token ratio 推到 sequence likelihood,GSPO 声称 sequence-level clipping 能提升效率并稳定 MoE RL。
DrGRPO 则是对 GRPO 长度偏置的修正,Understanding R1-Zero-Like Training 指出 GRPO 会鼓励错误长答案变长,并用 DrGRPO 改善 token efficiency。脉络上看,算法不是越来越复杂,而是围绕“方差、长度偏置、有效梯度、MoE 稳定性、系统可实现性”反复改写优化粒度。
OPD(On-policy / Online Policy Distillation):RLVR 与 distillation 之间的第三条路线
若将 post-training 划分为三条数据流,差异在于 feedback 来源与密度,而非是否存在 rollout:
- RLVR / PPO / GRPO:学生 rollout → verifier / reward → policy gradient(
A · log π及 clip、KL) - SFT / offline distillation:教师数据或教师输出 → 离线监督,但 teacher 分布与 student 当前分布不一致,存在 off-policy distribution shift
- OPD(On-policy / Online Policy Distillation):学生 rollout 自己的轨迹 → teacher 在这些 on-policy 轨迹上提供密集反馈 → distillation update
OPD 的动机来自两条路线的各自短板。SFT 和 offline distillation 的问题是:teacher 数据来自 teacher 自己的分布,学生一旦偏离训练分布,纠错信号就变弱——distribution shift 会削弱纠错信号的有效性。PPO / GRPO / RLVR 则相反:on-policy 数据生成可行,但 reward 常稀疏、方差高,长链推理与 agent trajectory 中 credit assignment 困难——模型仅知最终失败,难以定位需修正的中间步骤。OPD 结合两者:由 student 执行 rollout,在 student 实际到达的状态上由 teacher 提供密集监督。
与 RL 的关系需单独说明。OPD 保留 on-policy 数据生成,可缓解 off-policy distribution shift;但通常不直接优化 A · log π,也不一定采用 value model、advantage、KL penalty 等 RLHF 结构。其形式更接近将 teacher feedback 作为 dense reward / dense target,以 teacher 局部偏好替代稀疏 verifier 信号,降低 credit assignment 难度。因此 OPD 不宜简单归为 PPO / GRPO 变体,而应视为连接 RL、distillation、reasoning supervision 的 post-training 路线。
2026 年已有若干工作从不同侧面验证这条路线。DiffusionOPD 将 OPD 扩展至 diffusion model 的多任务 RL / 后训练:task-specific teachers 先独立学习,再沿 student rollout distill 至统一 student,表明 OPD 不局限于离散 token LLM,亦可推广至连续状态生成模型。
OmniOPD 提出 logit-free OPD,用 chunk-level semantic verification 替代直接 teacher logits——teacher 无需暴露 token logits,黑盒 teacher 或语义验证亦可构造密集反馈。SG-OPD 用 verifier 作为 teacher feedback 的 trust signal,表明 token-level preference 并非总可靠,需 gating 或 verifier 校准。
POPD / TOPD(Are Full Rollouts Necessary for On-Policy Distillation?)指出 OPD 不一定需要完整 rollout:Progressive OPD 和 Truncated OPD 可控制 rollout horizon,论文报告 TOPD 只用 10% rollout horizon 可接近 OPD 效果,POPD 最高带来 3x 训练效率提升。CaMOPD 做 Multi-Teacher On-Policy Distillation,用于 general capability recovery 与 domain preservation,表明 OPD 可承载多 teacher 能力整合,但需处理不同 teacher / domain 的梯度冲突。
OPD 的关键变量包括 teacher feedback 的形态——token-level logits、chunk-level semantic feedback、verifier-gated feedback、multi-teacher feedback、truncated / progressive horizon feedback。形态不同,系统接口、延迟预算与稳定性策略亦不同。
亦需说明:OPD 并非对所有场景均适用,它会把 RLVR 中的 reward bottleneck 转移为 teacher service bottleneck——teacher 推理成本高;teacher logits / chunk feedback 难以低延迟回传;teacher 与 student 的 tokenizer / chat template 不一致会带来对齐问题;teacher feedback 可能在学生错误轨迹后半段失真;多 teacher 可能产生梯度冲突。工程上,OPD 的收益取决于 teacher 服务是否具备与 rollout 同等的扩展、观测与版本化能力。
Agentic RL 的训练语义挑战
Agentic RL 的首要难点是多轮 credit assignment:最终 reward 可能仅在任务完成时出现,中间则包含 search、tool call、file edit、terminal execution、browser observation 等步骤。将整条 trajectory 拼接为单一 sequence 会混淆语义边界;tool observation 不宜作为 model action 参与 loss 计算。
框架内路线与零侵入路线正在形成对照组。Relax 在工程层提供 BaseInteractionEnv、multi-turn loss masking、VLM context carry-over,将 execute → observe → decide 抽象为框架原语。SkyRL-Agent 表明 agent rollout 需专用 dispatcher:SkyRL-Agent 在 SWE-Bench Verified 上将 Qwen3-32B 从 24.4% Pass@1 训练至 39.4%,并报告异步 pipeline dispatcher 比 naive async batching 快 1.55x。
零侵入路线将问题表述为 如何从任意 agent 代码中稳定抽取 training transition。Agent Lightning 的 LightningRL 将 agent 执行建模为 MDP,引入 credit assignment module,将 agent 轨迹拆分为 training transition;其价值在于 agent execution 与 training 的 disaggregation,LangChain、AutoGen、OpenAI Agents SDK 等可通过 minimal-change 接入。rLLM 采用相同思路,并强调 inference-native token capture:LiteLLM proxy 或 SDK 从 vLLM 获取 token id 与 logprob,写入 SQLite store,再交由 verl 后端更新——同一 agent 代码可用于 eval 与 train。rLLM 的 @rllm.rollout + AgentWorkflowEngine 表明零侵入方案亦适用于 solver–judge、planner–executor 等多 agent workflow。
Retokenization drift 是零侵入接入中的常见问题:agent 侧 API tokenization、训练侧 tokenizer、工具模板和 chat template 不一致时,logprob / mask / reward 对齐会发生漂移。rLLM 的应对是从 inference server 侧取 token id,Agent Lightning 强调 episode schema 与 credit assignment,框架内路线靠 loss masking 和 env observation 边界。三条路线最终都要收敛到同一数据结构:显式区分 model action 与 environment observation,并保留原始 message 与 token span。
稳定性挑战:信号、策略与轨迹的失配
entropy collapse 指 policy 过早确定化:reward 稀疏而更新置信度高时,分布熵持续下降,探索减少、梯度减弱,policy 收敛至局部策略。OPEFO 从 token-level entropy flow 解释该现象,认为 entropy-decreasing tokens 长期主导 entropy-increasing tokens,需按熵贡献重标定更新;另有工作通过 dynamic clipping 调控 entropy。
reward hacking 属于 Goodhart 问题:verifier、unit test、LLM-as-judge 均为代理目标,模型可能优化代理指标而非任务本身;在代码与 agent 任务中表现为修改测试、利用答案泄漏、生成格式正确但语义无效的输出。KL 异常通常来自 reward 过强、reference 约束过弱或采样分布突变;KL 仅约束分布距离,不约束工具权限与任务语义。
长尾生成兼具系统稳定性与算法层面含义:长输出可能包含有效推理,也可能来自过度思考或长度投机;FP8-RL 将 rollout 视为瓶颈,W8A8 + FP8 KV-cache + TIS/MIS correction 报告最高 44% rollout throughput gain。大 MoE RL collapse 还涉及 expert routing、低精度 rollout、train-inference mismatch 与负载不均;GSPO、FP8 correction、R3/Routing Replay、Relax 的 R3 支持均旨在控制 routing 与 rollout 偏差对 policy update 的放大效应。
OPD 亦可从稳定性角度分析:其缓解 RLVR 的 sparse reward 与高方差,但引入 teacher-feedback stability 问题。标准 OPD 假设 teacher 在学生轨迹上的 token-level preference 可靠;学生早期轨迹质量通常较低时,teacher 对后续 token 的局部 logits 未必指向有效修正方向——feedback 可能含噪或产生误导。SG-OPD、OmniOPD、TOPD/POPD 分别从 verifier gating、logit-free chunk feedback、rollout horizon control 三个方向处理该问题,表明 OPD 工程化需显式设计 feedback 可信度与 horizon 边界,而非仅替换 teacher。
系统架构权衡:同步、异步与部署边界
同步训练的优点是 on-policy 语义明确:一批 rollout 来自同一 policy,KL、advantage、clip 的解释较为直接;slime / vime 等单控制器路线将 Megatron 训练、SGLang 或 vLLM rollout、Data Buffer 置于显式路径,调试与正确性验证相对清晰。缺点是长尾 generation 导致整批等待,rollout 越长、工具越慢,GPU bubble 越显著。
异步路线的代表为 AReaL 与 Relax:AReaL 完全解耦 generation 与 training,报告最高 2.57x speedup;Relax 通过 TransferQueue 与 configurable staleness,覆盖 on-policy 至 fully async 的连续谱,论文报告 Qwen3-Omni-30B fully async 相比 colocated deployment 2.00x speedup。
colocated deployment 适用于小集群与严格 on-policy,actor / rollout 复用 GPU,权重同步简单;disaggregated deployment 适用于大规模与 agentic workload,rollout、reward、env 可独立扩缩,但需处理 staleness、policy publish / weight transfer 与故障隔离。SGLang 侧重结构化、多轮、KV 复用与复杂程序执行,SGLang 报告最高 6.4x throughput;vLLM 侧重通用 serving、PagedAttention 与生态覆盖,vLLM 报告 2–4x throughput。框架选型应基于 workload 是单轮大批量、长上下文多轮还是工具环境驱动,而非单一吞吐 benchmark。
扩展规律:从单点吞吐到 loop goodput
后训练 scaling 与预训练不同:预训练主要是 token、参数、算力的平滑缩放;RL post-training 是 policy、rollout、reward、environment、judge、checkpoint、policy publish / weight transfer 的全链路缩放。扩展瓶颈也不是单个 GPU TFLOPS,而是 loop goodput:多少有效 trajectory 能在单位时间内产生、被打分、被正确归因并进入更新。
OpenRLHF 早期就指出 RLHF 不是单模型训练,而是四模型协调问题,因而用 Ray、vLLM、DeepSpeed 重做 70B+ 调度。HybridFlow / verl 将 RLHF dataflow 中各 NN 节点扩展为分布式训练或生成程序,并以 hybrid controller 表达依赖,报告 1.53x–20.57x throughput improvement;核心是 3D-HybridEngine 降低 train / generate resharding 成本。
NeMo-RL 的功能列表 / roadmap 面向千卡生产:NeMo-RL 支持 DTensor、Megatron、vLLM、SGLang、Megatron inference、FP8、Async RL、environment isolation,NeMo-Aligner 时代已披露千 GPU 规模下 340B / 405B 级模型训练能力。AReaL-Hex 指出异构 GPU 下 rollout generation、reward、policy update 的 compute / memory / communication profile 不同,调度需按 stage 匹配资源,论文报告同预算最高 1.50x throughput、等吞吐最高 1.46x cost reduction。
概括而言,RL scaling 更接近全链路吞吐规律,受最慢环节、长尾、staleness 与失败恢复共同约束。
生态格局:工程路线分化,核心抽象收敛
上文「开源与工业路线」已按技术特征梳理各框架。本节不再重复框架清单,而是从演化路径看:当前生态更像四条路线并行,而不是单一框架收敛。
slime 谱系的技术哲学是少抽象、强原生:slime 直接暴露 Megatron 与 SGLang 参数,强调 Data Buffer、workflow、reward / verifier 的显式路径;Miles 沿此路线补 FP8、R3、speculative RL 与企业级 MoE 稳定性;vime 则把 slime 训练栈横向接入 vLLM + vllm-router 生态。这一路线适合已有 Megatron 训练能力、需要低层可控性的团队,代价是 agent environment、异步调度和服务治理通常要在外层补。
verl 谱系更像可组合 dataflow 承载层:HybridFlow / 3D-HybridEngine 让 train、generate、reward 节点可以按依赖组合,EasyR1、VeRL-Omni、uni-agent 分别把它推向多模态 RLVR、diffusion / omni-modal、agent env 统一层。它的优势是研究原型和系统扩展都能挂在同一抽象下,代价是抽象层较重,深度定制时需理解 controller、worker、后端 resharding 的边界。
Ray 系(OpenRLHF、SkyRL、AReaL、ROLL)强调异构 worker 调度与执行弹性,适合 rollout、reward、environment、trainer 分工复杂的 workload。Ray actor / task 让多角色生命周期更自然,但正确性不会自动获得;policy version、staleness、queue backlog、partial retry、跨服务观测仍需框架显式建模。
独立工业 / infra 路线继续分化:Relax 代表 Ray Serve + TransferQueue 的服务化异步;NeMo-RL 绑定 NVIDIA 硬件、Megatron、DTensor、checkpoint 与 worker isolation;ROLL 是 Ray + Megatron-Core + vLLM / SGLang 的全栈路线;Forge 公开材料体现 agent-native gateway、Data Pool 与 scaffold 解耦。
这些路线未必会收敛到相同代码库,但会在 episode schema、reward contract、rollout service、policy publish / weight sync、environment isolation 与 observability 上趋同。真正继续分化的是训练后端、推理后端、调度控制面和组织已有 infra 的方式。
趋势收束:下一步值得关注什么
从以上链条看,未来 12 个月可能广泛采用的不是单一方法,而是四类能力:异步 agent RL、过程奖励模型(PRM)、OPD / on-policy distillation,以及生产态推理集群上的低优先级 rollout。PRM 针对 reward 稀疏,异步 agent RL 针对 rollout goodput,OPD 通过 teacher dense feedback 处理长程 credit assignment 与 RL 方差,生产态 rollout 则针对大规模生成的资源弹性与成本。
OPD 可与 PRM、verifier、black-box teacher 组合:PRM 提供过程性判断,teacher 提供局部改写方向,verifier 提供 gating。其定位可能介于 RLVR 与 distillation 之间。异步 agent RL 已有 AReaL、Relax、SkyRL-Agent、DORA 等系统实践:DORA 报告 rollout 占 step time 50–80%,multi-version streaming rollout 在保持 intra-trajectory policy consistency、data integrity、bounded staleness 的同时消除 bubble,系统吞吐提升 2–3x、工业规模加速 2–4x;此类方案要求框架原生支持 policy version 与 staleness 语义。
PRM 可作为 reward hacking 的补充:纯 outcome reward 稀疏,LLM-as-judge 存在 exploit 风险,过程奖励可将长链推理、工具调用、代码修改分解为更细粒度监督,代价包括标注、judge 稳定性与过程过拟合。生产态 inference rollout 可能先在 coding agent、长程 evaluation、synthetic data generation 中落地,因为这些 workload 对 p99 用户延迟不敏感,但需要大规模并发生成;关键约束是 priority isolation、policy version pinning、logprob / trace export 与 preemption 后的样本完整性。
多智能体 RL 可能在 communication cost、self-play、simulated user 等方向先出现,Agent-GSPO、MUA-RL 表明 token economy 与动态用户意图将进入 reward 设计。omni-modal RL 持续扩展,Relax 与 NeMo-RL 已将 VLM / omni-modal 纳入主线;VeRL-Omni 表明 diffusion / omni-modal post-training 可与 LLM RL 共享部分 orchestration。
零侵入 Agent RL(Agent Lightning、rLLM)与框架内 agent 层(uni-agent、Forge gateway)并行发展:前者适用于 scaffold 规模大、需复用现有 agent 资产的场景;后者适用于 env 可控、内循环吞吐要求高的场景。diffusion model RL 可能在图像 / 视频生成质量与偏好优化中先行落地,与 agentic RL 的统一仍需 episode 与 reward 抽象进一步泛化。
持续跟踪时,可将重点放在这些项目是否补齐共同抽象:DCPO、DORA、SkyRL-Agent、NeMo-Aligner / NeMo-RL、Forge / CISPO、FP8-RL、EasyR1、VeRL-Omni、Miles R3、vime train–inference parity、production-inference rollout。
落地:目标架构与选型
目标架构:四层分工
观点:未来后训练 RL 系统不会只有一个 trainer 层,而会自然分成应用、环境 / reward、RL orchestration、model runtime 四层。
分析线索:从四层架构看每层职责和边界。
后训练 RL 系统可划分为四层:
1 | Application / Agent Layer |
分层后,各层边界更为明确。
Application 层中的 Env State(环境状态,有时也称 workspace)是 agent 执行任务时可读写的状态容器:coding 场景下是代码仓库与挂载目录,terminal 场景下是沙箱 cwd,browser 场景下是页面 DOM 与交互状态。它与 Task(目标)、Tool(可调用能力)并列,是 tool 作用对象与中间 observation 的载体,不在主训练数据流链上,但为 Rollout 提供执行上下文。
第一,Agent 应用不宜直接绑定特定 trainer,而应以标准 trace 记录任务轨迹、工具调用、观察结果与最终 artifact,供 RL 层消费。
第二,reward / verifier 应作为独立资产,具备版本化、可回放、可审计的 domain contract 属性,而非嵌入单次训练脚本的条件逻辑。
第三,RL orchestration 不应假设 rollout 仅为本地 model.generate(),而需处理 policy serving 更新、异步请求、权重同步 / 版本发布、失败重试与环境并发。
第四,model runtime 层持续专门化,并同时覆盖训练与推理两侧:Training Engine(Megatron / FSDP 等,供 Trainer 执行 update forward / backward)与 Inference Engine(vLLM / SGLang 等,供 Rollout 执行 generation forward);MoE、长上下文、MTP / speculative decoding、FP8 / FP4、context parallel、expert parallel、KV cache 与通信拓扑均影响 RL goodput。
框架选型:从瓶颈出发
观点:框架选型应该从当前瓶颈出发,而不是从框架名或算法名出发。
分析线索:用 checklist 判断当前系统缺的是 rollout、environment、reward、observability 还是大规模 runtime。
评估 RL 框架或内部系统时,宜优先检查以下问题:
-
Rollout 怎么做
是否支持 vLLM / SGLang 等高吞吐后端?权重同步 / 版本发布是阻塞还是异步?长尾 generation 怎么处理? -
环境怎么接
是否能表达多轮状态、工具调用、文件系统、终端、浏览器、异常和 timeout?环境失败是否会导致整轮训练中断? -
Reward 怎么版本化
reward breakdown 是否记录?judge 版本是否入库?同一批 trajectory 是否可用新 reward replay? -
数据结构是否足够完整
是否保存 old logprob、ref logprob、采样参数、policy checkpoint、trace id、env version?是否可复现指定 trajectory? -
异步边界在哪里
rollout 与 update 是否可 overlap?reward / judge 是否可异步?checkpoint 是否阻塞主循环? -
资源放置是否可控
训练、推理、reward、环境 worker 能否分别申请资源?MoE / EP / TP / PP 是否能感知拓扑? -
失败是否局部化
单条 trajectory 失败、单个 sandbox 阻塞、单个 vLLM worker 异常时,是局部重试还是整个 job 重启? -
观测是否面向 RL 训练链路
除了 loss、reward 均值,有没有 p99 latency、timeout rate、tool error taxonomy、reward distribution drift、policy version 对比? -
算法改动成本多高
改 advantage、KL、reward shaping、loss aggregation、采样策略时,是改一个模块,还是要穿透整个框架? -
上线回流路径是否存在
线上 agent trace 是否可进入离线训练?训练中 eval bad case 是否可回流至数据构造? -
Rollout / reward / env 是否能独立扩缩
rollout generation、reward / judge、environment worker 能否分别申请资源、独立扩容和故障隔离?还是必须随 trainer job 同生共死? -
Rollout 是否必须绑定训练集群
rollout 是否只能接 job 内嵌的 vLLM / SGLang worker,还是可以接生产态 inference gateway 或 serverless inference pool?若接外部推理平台,policy publish / version pinning 和 trace 回传路径是否明确? -
是否记录 policy version、sample staleness、queue delay
每条 trajectory 是否带 policy version tag?样本进入 update 时 staleness 是否可度量?rollout / reward / inference 各段 queue delay 是否入库? -
是否支持 backpressure、partial retry、timeout cleanup
下游 reward 或 judge 慢时,rollout 是否会 backpressure?单条 trajectory 超时能否 partial retry 或局部丢弃,而不是阻塞整批? -
调度层是否能区分异构 worker
trainer GPU、rollout GPU、CPU env worker、judge worker 能否分别放置、扩缩和监控?placement 是否感知拓扑和资源画像差异? -
复用生产推理集群时,训练所需字段能否完整回传
若 rollout 走外部 inference API,logprob、sampling params、token trace、model version 是否能稳定返回,满足 advantage 估计和 off-policy correction? -
是否支持 Teacher / Distillation Service
OPD 场景下,框架是否能在 student rollout 轨迹上调用 teacher,并回传 token / chunk / step 级反馈?是否支持 teacher version、feedback span、teacher-student tokenizer mapping? -
OPD feedback 是否可观测和可回放
teacher feedback、verifier gating、teacher / verifier disagreement、feedback latency 是否入库?同一批 trajectory 能否用不同 teacher 或不同 feedback policy replay?
结论
观点:后训练 RL 的长期积累将沉淀于系统资产,而非单个 trainer repo。
分析线索:从链路质量、runtime 化、agentic 生产系统化、可验证 reward、goodput 五个角度收束。
第一,后训练 RL 的壁垒正从单个算法转向链路质量。算法公开速度快,但高质量环境、reward contract、trace schema、failure taxonomy 与 replay / eval 体系复制成本较高。
第二,RL 框架的竞争维度正从内置训练目标扩展至训练链路组织能力。PPO / GRPO 为入口,难点在于 rollout、reward、environment、trainer、serving、checkpoint、observability 在大规模下的协同稳定性。
第三,agentic RL 推动训练系统接近生产系统。环境、工具与失败模式均为真实场景,除 GPU 计算外,还需处理权限、隔离、超时、状态污染、外部依赖与复现性。
第四,可验证 reward 将成为 post-training 的核心资产。其效果受 verifier 设计约束:verifier 越强,模型越可能围绕 verifier 优化;verifier、hidden eval、过程审计、人工抽检与 reward 多样性需一并设计。
第五,RL infra 的优化目标应为 goodput,而非峰值吞吐。大规模 RL job 的主要成本来自等待、重启、长尾、同步、I/O、checkpoint 与环境失败;降低失败率、缩短恢复时间、支持归因通常比单点 benchmark 更具实际价值。
概括而言:
LLM post-training RL 的成熟实践通常不只维护 trainer repo,而维护任务环境、reward contract、trajectory store、RL runtime 与 eval / replay 组成的系统。
RL 框架仅为其中一层;主要积累在完整链路中。
附录
后训练 Objective 速查
社区和框架文档常用方法名(DPO、GRPO)指代一套 post-training 配方。落到 trainer,差别在 objective 怎么写、要不要在线 rollout、feedback 来自 reward 还是 teacher,以及 advantage / KL / clip 如何进梯度。粗略可分三类:
- Preference objective(DPO、KTO):直接在 preference 或 good/bad 信号上优化 logprob,不跑 rollout
- Policy-gradient objective(PPO、GRPO 等):先采样 trajectory,再按 reward 估 advantage,以
A · log π(及 clip、KL)做 backward;PPO 另训 value head,GRPO 及变体去掉 critic - On-policy distillation objective(OPD):学生按当前 policy rollout,teacher 沿学生轨迹提供 token / chunk / step 级 feedback,优化形式更接近 dense distillation target
下表按方法名汇总各 objective / feedback 路线的关键形式。SimPO、ORPO、RAFT 等变体未列,差异多在 advantage baseline、KL 注入位置、clip 粒度与 feedback 密度。
| 类型 | 方法 | 来源 | Objective 要点 |
|---|---|---|---|
| Preference / 离线 | DPO | Rafailov et al., 2023 | 成对 preference 的 logprob 差 + reference 约束 |
| Preference / 离线 | KTO | Ethayarajh et al., 2024 | 非成对 good/bad 的 preference objective |
| Online RL | PPO | InstructGPT / Ouyang et al., 2022 | clipped surrogate + value loss + entropy bonus |
| Online RL | GRPO | DeepSeek-Math, 2024 → R1, 2025 | 组内相对 advantage × log π(常带 clip) |
| Online RL | ReMax | Li et al., ICML 2024 | (r - r_greedy) · log π |
| Online RL | RLOO | Ahmadian et al. / Cohere, 2024 | leave-one-out advantage × log π;KL 常进 reward |
| Online RL | REINFORCE++ | Hu et al., 2025 | 全局 batch 归一化 advantage × log π |
| RLVR 工程 | DAPO | ByteDance, 2025 | decoupled clip、dynamic sampling、overlong shaping |
| RLVR 工程 | CISPO | MiniMax-M1, 2025 | clip importance sampling weights |
| RLVR 工程 | GSPO | Qwen, 2025 | sequence-level ratio clip |
| RLVR 工程 | DrGRPO | Understanding R1-Zero-Like Training, 2025 | 修正 GRPO advantage 的长度偏置 |
| On-policy / online distillation | OPD | POPD / TOPD 等 2026 工作 | 学生按自身 policy rollout,teacher 沿学生轨迹提供密集 token / chunk / step feedback |
OPD 与 RLVR:二者均使用 student 的 on-policy trajectory。RLVR 主要从 reward / verifier 获得稀疏或标量反馈;OPD 从 teacher 获得更密集的 distillation 信号,形式为 on-policy 数据生成 + distillation objective。