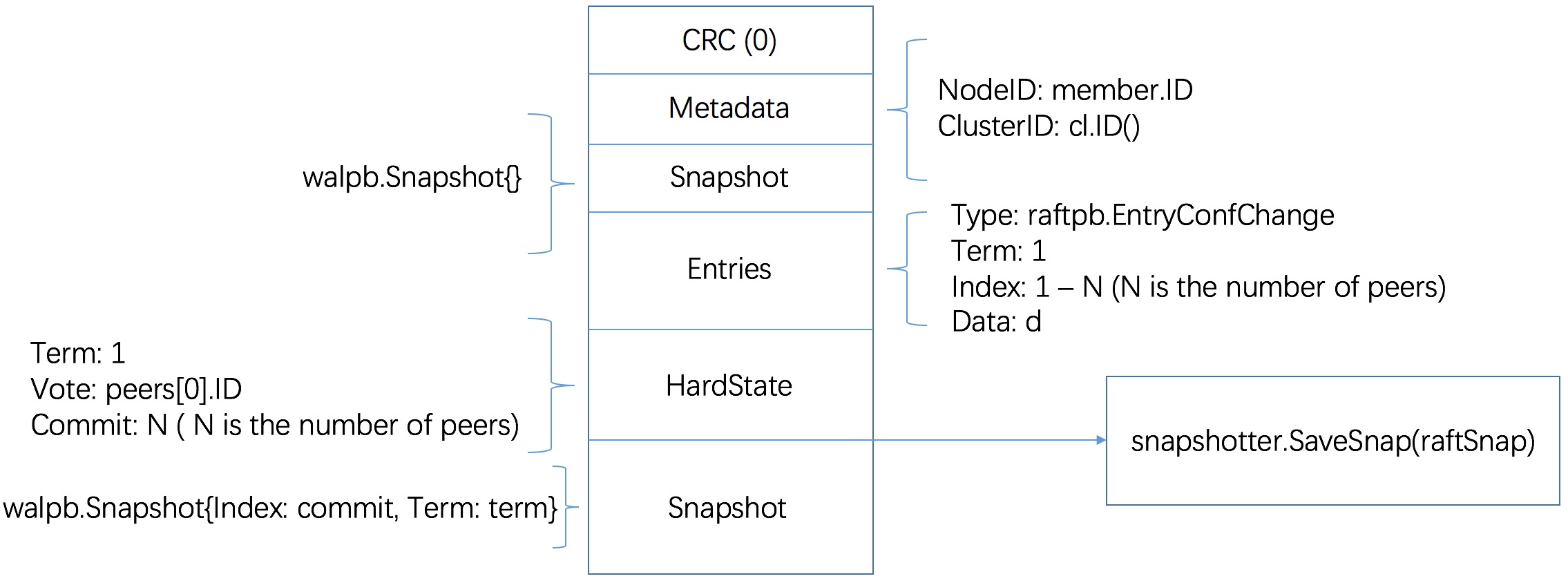
func(s *kvServer)Put(ctx context.Context, r *pb.PutRequest)(*pb.PutResponse, error)
v3_server.go
1
func(s *EtcdServer)Put(ctx context.Context, r *pb.PutRequest)(*pb.PutResponse, error)
v3_server.go
1
func(s *EtcdServer)processInternalRaftRequest(ctx context.Context, r pb.InternalRaftRequest)(*applyResult, error)
v3_server.go
1
func (s *EtcdServer) processInternalRaftRequestOnce(ctx context.Context, r pb.InternalRaftRequest) (*applyResult, error)
注册一个等待 id;完成之后调用 s.w.Trigger 触发完成 or GC ch := s.w.Register(id)
raft propose (提议写入数据)
1 2
// propose PutRequest s.r.Propose(cctx, data)
node.go
1
func (n *node) Propose(ctx context.Context, data []byte) error
n.step 往 propc 通道传入数据
node run main roop
1 2 3 4 5 6 7 8 9
func(n *node)run(r *raft) { ... case m := <-propc: r.logger.Infof("handle propc message") m.From = r.id r.Step(m) ... }
raft/raft.go
1 2 3 4 5 6 7 8
func(r *raft)Step(m pb.Message)error { ... default: r.step(r, m) ... }
r.step(r, m)
leader 和 follower 行为不同
对于 follower 来说
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
funcstepFollower(r *raft, m pb.Message) { ... case pb.MsgProp: if r.lead == None { r.logger.Infof("%x no leader at term %d; dropping proposal", r.id, r.Term) return } // forward to leader m.To = r.lead // just append to raft pb.Message ? r.send(m) ... }
func(r *raftNode)start(rh *raftReadyHandler) { ... case rd := <-r.Ready(): if rd.SoftState != nil { // lead has changed if lead := atomic.LoadUint64(&r.lead); rd.SoftState.Lead != raft.None && lead != rd.SoftState.Lead { r.mu.Lock() r.lt = time.Now() r.mu.Unlock() // prometheus record the count of leader changes leaderChanges.Inc() } if rd.SoftState.Lead == raft.None { hasLeader.Set(0) } else { hasLeader.Set(1) } // store current seen leader atomic.StoreUint64(&r.lead, rd.SoftState.Lead) islead = rd.RaftState == raft.StateLeader // raft handler rh.updateLeadership() } iflen(rd.ReadStates) != 0 { select { case r.readStateC <- rd.ReadStates[len(rd.ReadStates)-1]: case <-time.After(internalTimeout): plog.Warningf("timed out sending read state") case <-r.stopped: return } } raftDone := make(chanstruct{}, 1) ap := apply{ entries: rd.CommittedEntries, snapshot: rd.Snapshot, raftDone: raftDone, } updateCommittedIndex(&ap, rh) select { case r.applyc <- ap: case <-r.stopped: return } // the leader can write to its disk in parallel with replicating to the followers and them // writing to their disks. // For more details, check raft thesis 10.2.1 if islead { // gofail: var raftBeforeLeaderSend struct{} r.sendMessages(rd.Messages) } // gofail: var raftBeforeSave struct{} if err := r.storage.Save(rd.HardState, rd.Entries); err != nil { plog.Fatalf("raft save state and entries error: %v", err) } if !raft.IsEmptyHardState(rd.HardState) { proposalsCommitted.Set(float64(rd.HardState.Commit)) } // gofail: var raftAfterSave struct{} if !raft.IsEmptySnap(rd.Snapshot) { // gofail: var raftBeforeSaveSnap struct{} if err := r.storage.SaveSnap(rd.Snapshot); err != nil { plog.Fatalf("raft save snapshot error: %v", err) } // gofail: var raftAfterSaveSnap struct{} r.raftStorage.ApplySnapshot(rd.Snapshot) plog.Infof("raft applied incoming snapshot at index %d", rd.Snapshot.Metadata.Index) // gofail: var raftAfterApplySnap struct{} } r.raftStorage.Append(rd.Entries) if !islead { // gofail: var raftBeforeFollowerSend struct{} r.sendMessages(rd.Messages) } raftDone <- struct{}{} r.Advance() ... }
该部分会将 apply 的 message 放入 applc 通道中,最终由
server.go
1 2 3 4 5 6 7
func(s *EtcdServer)run() { ... case ap := <-s.r.apply(): f := func(context.Context) { s.applyAll(&ep, &ap) } sched.Schedule(f) ... }
func(fp *filePipeline)run() { deferclose(fp.errc) for { f, err := fp.alloc() if err != nil { fp.errc <- err return } select { // fp.filec 大小为 1 case fp.filec <- f: case <-fp.donec: os.Remove(f.Name()) f.Close() return } } }
查看 fp.alloc() 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14
func(fp *filePipeline)alloc()(f *fileutil.LockedFile, err error) { // count % 2 so this file isn't the same as the one last published fpath := filepath.Join(fp.dir, fmt.Sprintf("%d.tmp", fp.count%2)) if f, err = fileutil.LockFile(fpath, os.O_CREATE|os.O_WRONLY, fileutil.PrivateFileMode); err != nil { returnnil, err } if err = fileutil.Preallocate(f.File, fp.size, true); err != nil { plog.Errorf("failed to allocate space when creating new wal file (%v)", err) f.Close() returnnil, err } fp.count++ return f, nil }
可见预生成了 [0-1].tmp 文件,并对该文件加了锁,待调用 fp.Open() 方法获取使用
Cut 方法
wal 文件大小上限为 64MB
因此当写入消息之后, wal 文件大小 > 64MB 时,会调用 cut 方法
截断之前的 wal 文件,并生成新的 wal 文件用于写入
cut 的整体思路
截断当前使用的 wal 文件
从 file pipeline 中获取 tmp 文件
向 tmp 文件中写入必要的 headers
将 tmp 文件 rename to wal 文件,新文件名为 walName(w.seq()+1, w.enti+1)
// peer is the representative of a remote raft node. Local raft node sends // messages to the remote through peer. // Each peer has two underlying mechanisms to send out a message: stream and // pipeline. // A stream is a receiver initialized long-polling connection, which // is always open to transfer messages. Besides general stream, peer also has // a optimized stream for sending msgApp since msgApp accounts for large part // of all messages. Only raft leader uses the optimized stream to send msgApp // to the remote follower node. // A pipeline is a series of http clients that send http requests to the remote. // It is only used when the stream has not been established.
stream 每 100 ms 会重新尝试 dial remote peer,如果出现 request sent was ignored (cluster ID mismatch: remote[remote member id]=X-Etcd-Cluster-ID in http header, local=local cluster id) 错误的话,那么这个错误日志的打印频率将会很高,需要及时处理
上述方法从 –initial-cluster-token and –initial-cluster 这个两个启动参数中生成 Cluster ID 和各个 Member ID
NewClusterFromURLsMap 这个方法中调用 NewMember 生成 Member ID
首先来看 NewMember 方法
1
func NewMember(name string, peerURLs types.URLs, clusterName string, now *time.Time) *Member
核心思路
1 2 3
b []byte: peerUrls + clusterName + time hash := sha1.Sum(b) memberID: binary.BigEndian.Uint64(hash[:8])
Member ID 根据 peerUrls / clusterName / current_time 的 sha1 sum 值,取其前 8 个 bytes,为 16 位的 hex 数
回到 NewClusterFromURLsMap 方法中的 NewMember(代码如下)可见最后一个参数为 nil,即不加入时间因素,因此 NewClusterFromURLsMap 生成的 Member ID 是固定的
1
m := NewMember(name, urls, token, nil)
Member Add 生成的 Member ID
直接从 server 端看起 —— etcdserver/api/v3rpc/member.go 中的 MemberAdd 方法
可见如下代码
1 2 3 4 5 6 7 8 9
urls, err := types.NewURLs(r.PeerURLs) if err != nil { returnnil, rpctypes.ErrGRPCMemberBadURLs } now := time.Now() m := membership.NewMember("", urls, "", &now) if err = cs.server.AddMember(ctx, *m); err != nil { returnnil, togRPCError(err) }
m := membership.NewMember(“”, urls, “”, &now) 加入了当前时间,因此 Member ID 是不确定的
总结
cluster ID 仅生成一次,此后不会变化
通过 etcd 启动参数生成 (initial-cluster) 的 Member ID 固定
通过 Member add 生成的 Member ID 不确定
Member add 的时候,没有传递 member 的 name,因此 member add 成功时,member list 出来的 member item,新加入的 member 其 name 为空,且没有 client url,因该 member 尚未 publish 其 client url 到集群中
ReleaseLockTo releases the locks, which has smaller index than the given index except the largest one among them. For example, if WAL is holding lock 1,2,3,4,5,6, ReleaseLockTo(4) will release lock 1,2 but keep 3. ReleaseLockTo(5) will release 1,2,3 but keep 4.