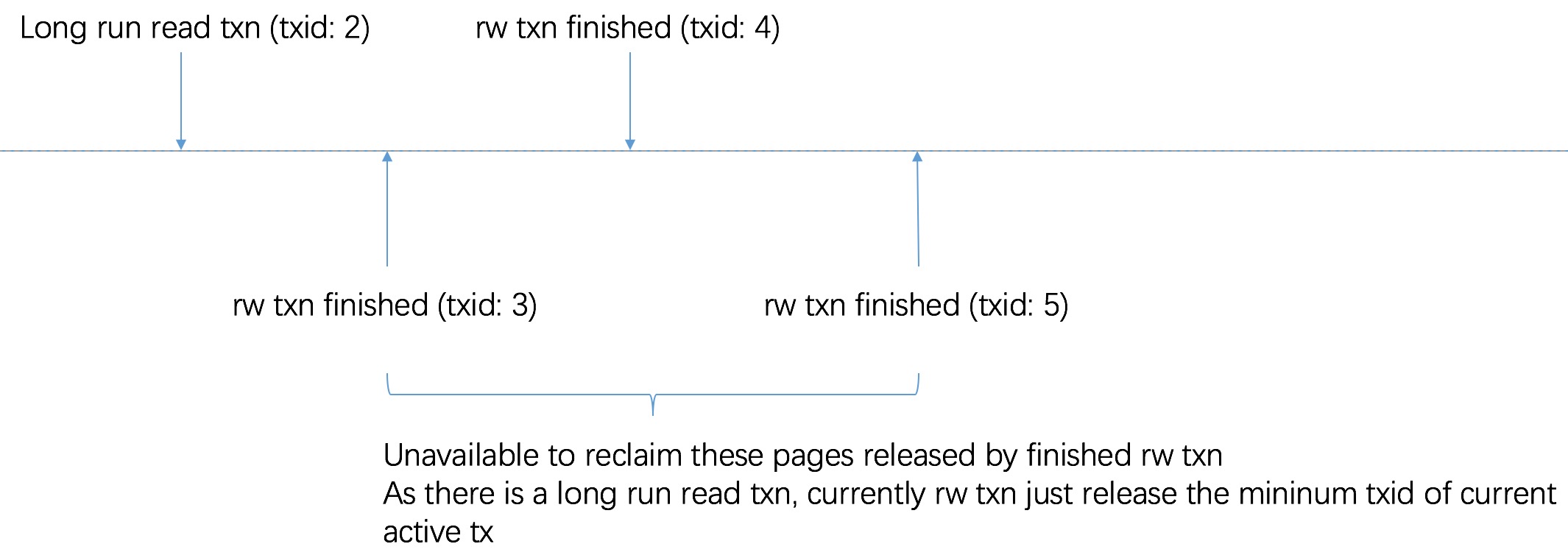
当然 long run read txn,会获取 mmap 读锁,因此当 rw txn 需要 mmap 写锁以扩大存储空间时,会阻塞
1
Read-only transactions and read-write transactions should not depend on one another and generally shouldn’t be opened simultaneously in the same goroutine. This can cause a deadlock as the read-write transaction needs to periodically re-map the data file but it cannot do so while a read-only transaction is open. https://github.com/boltdb/bolt#transactions
// freelist represents a list of all pages that are available for allocation. // It also tracks pages that have been freed but are still in use by open transactions. type freelist struct { ids []pgid // all free and available free page ids. // 记录每次 allocate 返回的 page id 与 txid 的对应关系 // allocate 返回的是连续分配的第一个 page id allocs map[pgid]txid // mapping of txid that allocated a pgid. pending map[txid]*txPending // mapping of soon-to-be free page ids by tx. cache map[pgid]bool// fast lookup of all free and pending page ids. }
freelist allocate 方法增加 txid 参数,用以记录 tx 分配的 page
1 2 3 4 5 6 7 8
// allocate returns the starting page id of a contiguous list of pages of a given size. // If a contiguous block cannot be found then 0 is returned. func(f *freelist)allocate(txid txid, n int)pgid { ... // 记录;仅记录分配的连续 page 的第一个 page id f.allocs[initial] = txid ... }
// free releases a page and its overflow for a given transaction id. // If the page is already free then a panic will occur. func(f *freelist)free(txid txid, p *page) { if p.id <= 1 { panic(fmt.Sprintf("cannot free page 0 or 1: %d", p.id)) } // Free page and all its overflow pages. txp := f.pending[txid] if txp == nil { txp = &txPending{} f.pending[txid] = txp } // 获取是分配给哪个 tx 使用的 allocTxid, ok := f.allocs[p.id] if ok { // 解除关联关系 delete(f.allocs, p.id) } elseif (p.flags & (freelistPageFlag | metaPageFlag)) != 0 { // Safe to claim txid as allocating since these types are private to txid. // 这两种页类型没记录 allocTxid = txid } // 释放连续页 for id := p.id; id <= p.id+pgid(p.overflow); id++ { // Verify that page is not already free. if f.cache[id] { panic(fmt.Sprintf("page %d already freed", id)) } // Add to the freelist and cache. // ids 与 alloctx 对应 txp.ids = append(txp.ids, id) txp.alloctx = append(txp.alloctx, allocTxid) f.cache[id] = true } }
// rollback removes the pages from a given pending tx. func(f *freelist)rollback(txid txid) { // Remove page ids from cache. txp := f.pending[txid] if txp == nil { return } var m pgids for i, pgid := range txp.ids { delete(f.cache, pgid) tx := txp.alloctx[i] // tx == 0 ?! if tx == 0 { continue } // 非当前 rollback 的 tx 分配的 page if tx != txid { // Pending free aborted; restore page back to alloc list. f.allocs[pgid] = tx } else { // Freed page was allocated by this txn; OK to throw away. // 归还 freelist ids m = append(m, pgid) } } // Remove pages from pending list and mark as free if allocated by txid. delete(f.pending, txid) sort.Sort(m) f.ids = pgids(f.ids).merge(m) }