// Validate the meta pages. We only return an error if both meta pages fail // validation, since meta0 failing validation means that it wasn't saved // properly -- but we can recover using meta1. And vice-versa. err0 := db.meta0.validate() err1 := db.meta1.validate() if err0 != nil && err1 != nil { return err0 }
说直接一点儿,boltdb 使用 mmap 把一个名为 db 的文件映射到内存中的 []byte 数组,然后直接操作内存,但是不管怎么说是外部存储,最终还是要落盘的,所以呢推测是用了 B+ tree,然后把写入的内容组织成 page,使用指针操作,这块代码有点像 C 其实
// allocate returns the starting page id of a contiguous list of pages of a given size. // If a contiguous block cannot be found then 0 is returned. func(f *freelist)allocate(n int)pgid { iflen(f.ids) == 0 { return0 } var initial, previd pgid for i, id := range f.ids { if id <= 1 { panic(fmt.Sprintf("invalid page allocation: %d", id)) } // Reset initial page if this is not contiguous. if previd == 0 || id-previd != 1 { initial = id } // If we found a contiguous block then remove it and return it. if (id-initial)+1 == pgid(n) { // If we're allocating off the beginning then take the fast path // and just adjust the existing slice. This will use extra memory // temporarily but the append() in free() will realloc the slice // as is necessary. // 将已分配的连续页移出 free list 记录表 (ids) // 并释放 ids 空间 if (i + 1) == n { f.ids = f.ids[i+1:] } else { copy(f.ids[i-n+1:], f.ids[i+1:]) f.ids = f.ids[:len(f.ids)-n] } // Remove from the free cache. // 移出 free list cache for i := pgid(0); i < pgid(n); i++ { delete(f.cache, initial+i) } // 返回起始页 return initial } previd = id } return0 }
// read initializes the freelist from a freelist page. func(f *freelist)read(p *page) { // If the page.count is at the max uint16 value (64k) then it's considered // an overflow and the size of the freelist is stored as the first element. idx, count := 0, int(p.count) if count == 0xFFFF { idx = 1 count = int(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[0]) } // Copy the list of page ids from the freelist. if count == 0 { f.ids = nil } else { ids := ((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[idx:count] f.ids = make([]pgid, len(ids)) copy(f.ids, ids) // Make sure they're sorted. sort.Sort(pgids(f.ids)) } // Rebuild the page cache. f.reindex() }
// read initializes the freelist from a freelist page. func(f *freelist)read(p *page) { // If the page.count is at the max uint16 value (64k) then it's considered // an overflow and the size of the freelist is stored as the first element. // page 中的 count 怎么理解 ? // 看着像是 page 下面维护着一系列 pgid idx, count := 0, int(p.count) if count == 0xFFFF { idx = 1 count = int(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[0]) } // Copy the list of page ids from the freelist. if count == 0 { f.ids = nil } else { ids := ((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[idx:count] f.ids = make([]pgid, len(ids)) copy(f.ids, ids) // copy 结束之后,是否可以设置 ids = nil,帮助 gc ? // Make sure they're sorted. sort.Sort(pgids(f.ids)) } // Rebuild the page cache. f.reindex() }
freelist 的 reindex 实现,其实就是构造 cache,很直接的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// reindex rebuilds the free cache based on available and pending free lists. func(f *freelist)reindex() { // 既然已知大小的话,make 的时候为啥不指定 capacity // 好吧,我晕了,这个是 map,怎么指定大小?naive f.cache = make(map[pgid]bool) for _, id := range f.ids { f.cache[id] = true } // pending 记录了 tx 中使用过,未被释放的 page id for _, pendingIDs := range f.pending { for _, pendingID := range pendingIDs { f.cache[pendingID] = true } } }
func(db *DB)beginRWTx()(*Tx, error) { // If the database was opened with Options.ReadOnly, return an error. if db.readOnly { returnnil, ErrDatabaseReadOnly } // Obtain writer lock. This is released by the transaction when it closes. // This enforces only one writer transaction at a time. db.rwlock.Lock() // Once we have the writer lock then we can lock the meta pages so that // we can set up the transaction. db.metalock.Lock() defer db.metalock.Unlock() // Exit if the database is not open yet. if !db.opened { db.rwlock.Unlock() returnnil, ErrDatabaseNotOpen } // Create a transaction associated with the database. t := &Tx{writable: true} t.init(db) db.rwtx = t // Free any pages associated with closed read-only transactions. // 获取当前事务中的最小 txid var minid txid = 0xFFFFFFFFFFFFFFFF for _, t := range db.txs { if t.meta.txid < minid { minid = t.meta.txid } } // 释放该 txid 之前的 page if minid > 0 { db.freelist.release(minid - 1) } return t, nil }
查看 db.freelist.release 的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// release moves all page ids for a transaction id (or older) to the freelist. func(f *freelist)release(txid txid) { m := make(pgids, 0) for tid, ids := range f.pending { if tid <= txid { // Move transaction's pending pages to the available freelist. // Don't remove from the cache since the page is still free. m = append(m, ids...) delete(f.pending, tid) } } sort.Sort(m) // 可重新使用的 pending page 与当前可使用的 page merge sort f.ids = pgids(f.ids).merge(m) }
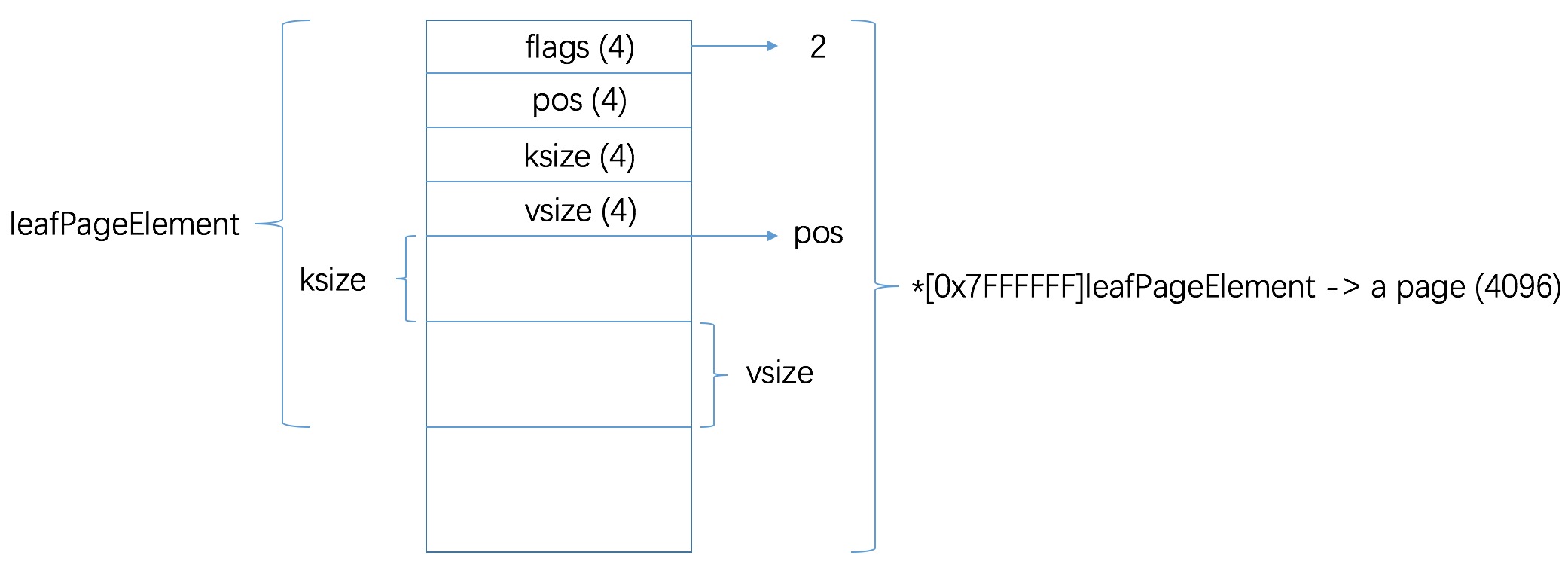
leafPageElement 结构
1 2 3 4 5 6 7 8
type leafPageElement struct { flags uint32// 4 bytes; 2 leafElement / 1 branchElement / 4 meta / pos uint32// 4 bytes ksize uint32// 4 bytes vsize uint32// 4 bytes // pos = 16 that remain space to store key and value // for example ksize = 8 that 64 bytes for key }
如图所示
即叶子节点中存储了 key 和 value
etcd
查看 mvcc/kvstore.go 的 func (s *store) put(key, value []byte, leaseID lease.LeaseID) 方法