etcd-raft-follower
to be cont 先写部分吧
MsgProp
Follower 收到 MsgProp 消息时,有成员发起选举,将该请求转发至 Leader;消息先 append 到 raft.msgs slice 中,注意后续所说的消息发送,均为 append 到 msgs 中,并未产生实际发送
MsgApp
Follower 收到 MsgApp 消息时,即有 Entries 写入时,重置 electionElapsed 为 0,设置其 Leader 为消息来的成员的 ID;调用 handleAppendEntries 方法处理 MsgApp 消息;handleAppendEntries 方法中向 m.From 发送 MsgAppResp 消息;消息中包含经过处理 MsgApp 后,当前节点的 Index;冲突时额外返回 Reject: true,RejectHint: lastIndex
maybeAppend: handleAppendEntries 方法中使用到的 maybeAppend 方法分析
(1)
firstIndex 会尝试从 unstable 的 snapshot 中获取 snapshot meta Index,如果 snapshot 为 nil(maybeFirstIndex),则从 storage 中获取 ents[0].Index
(2)
lastIndex 会尝试从 unstable 的 ents 中获取最后一个 entry 的 index,如果 unstable 的 ents 为空,则获取 unstable 的 snapshot meta index(maybeLastIndex),如果仍然获取不到,则从 storage 中获取最后一个 entry 的 Index
看明白最基础的方法 firstIndex 和 lastIndex 后,继续往下
(3)
term 尝试获取 index 为 i 的 entry 的 term,entries 的第一个 index 为 dummy index,即每次收到 MsgApp 消息时,m.Index 为 dummy entry (index),后续为真正的 entries (m.Ents);dummy index <= i <= lastIndex,如果 index i 不位于该范围中,显然无法找到对应的 term;maybeTerm 尝试在 unstable 中获取 index 为 i 的 entry 的 term,unstable 中无法找到的话,从 storage 中查找
(4)
matchTerm(i uint64, term Term) 的实现,首先尝试获取 index i 的 term,随后匹配是否等于 term
(5)
findConflict 的实现,对 ents 中的每个 entry 调用 matchTerm 方法,Index 升序遍历,遇到 unmatch的 (即遇到相同 Index 不同 Term 的 entry 认为 conflict),如果这个 unmatch 的 entry 的 Index <= lastIndex,则有 conflict,返回第一个 conflict entry 的 Index;如果这个 unmatch 的 entry 的 Index > lastIndex,则认为是新的未包含的 entry,则返回第一个新的 entry 的 Index;如果均 match 则返回 0
(6)
maybeAppend(m.Index, m.LogTerm, m.Commit, m.Entries…) 的实现,内部会首先判断 matchTerm(m.Index, m.LogTerm),过了之后,会对每个 entry findConflict,没有 confict 则没啥好添加的,有 conflict,可能是真 conlict 也可能是包含了新的 entries,统一调用 append 方法加入到 unstable 中;注意这是 Follower 的行为,Follower 会使用 Leader 发来的 MsgApp 改写自己本地的 entries;Leader 发来的 MsgApp 中包含了其已经 commited 的 Index 信息,Follower 使用 commited 和 MsgApp 中的最后 Index 中小的那个 Index 作为能 committed 的 index
lastnewi = index + uint64(len(ents))
commitTo(min(commited, lastnewi))
如果 tocommit > l.lastIndex() 会 panic
(7)
综上
- 接收到 MsgHeartbeat 消息会更新 commited
- 接收到 MsgApp 消息可能会更新 commited
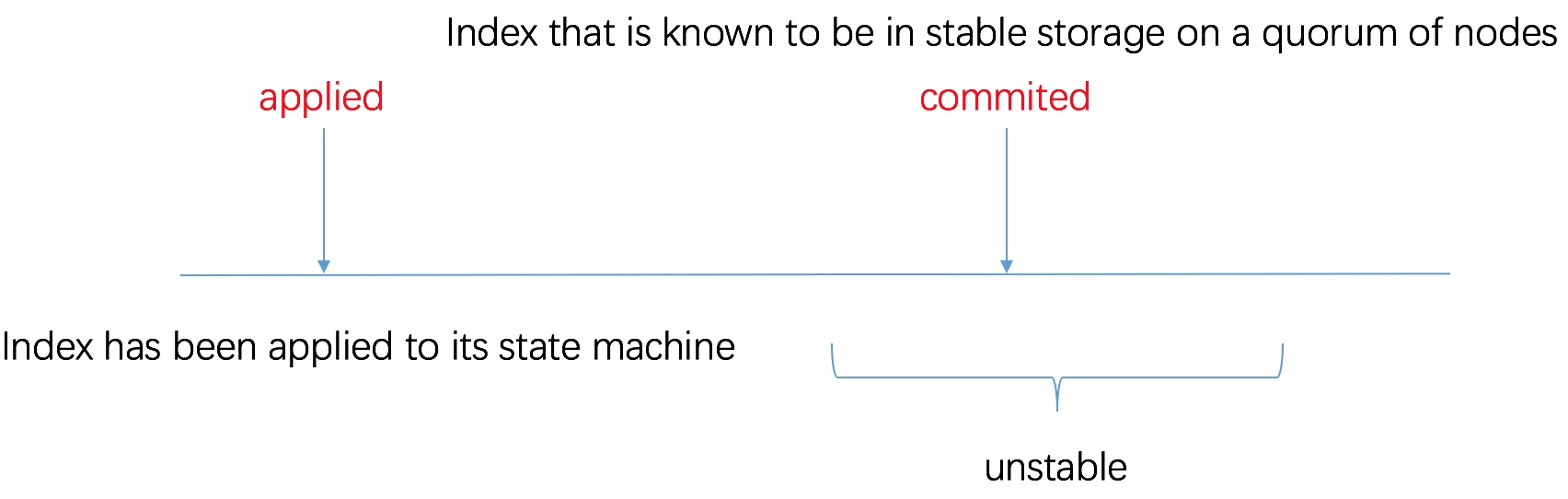
FAQ: unstable 什么时候会 stable?
在 node 的 main for loop 中,首先会从 raftlog 中获取 ready to apply 的 entries (即 unstable 和 nextEnts),将其放入 readyc 通道后,等待 advancec 通道消息;当外部 apply 结束后,调用 node.Advance() 方法,node 获取到 advancec 通道中的消息,开始执行 raftlog 的 apply 更新 apply index 和 stable to 将 unstable 变为 stable
raftlog 的逻辑图如下 (没写 snapshot 部分)
MsgHeartbeat
Follower 收到 MsgHeartbeat 消息时,重置 electionElapsed 为 0,设置其 Leader 为消息来的成员的 ID;commitTo MsgHeartbeat 中的 commited index,并向 Leader 回复 MsgHeartbeatResp 消息
MsgReadIndex
Follower 收到 MsgReadIndex 消息,将请求转发至 Leader;Leader 返回 MsgReadIndexResp 消息,有且仅有 1 Entry,返回已到达一致性的 Index (consistency=l);线性 / 序列化,貌似是个术语待查
Follower 收到 MsgReadIndexResp 消息,有且仅有 1 Entry,将其加入 readStates 中
1 | r.readStates = append(r.readStates, ReadState{Index: m.Index, RequestCtx: m.Entries[0].Data}) |
FAQ: 那么 msgs 什么时候会被发送
回到 node 的 main forloop,在 rd = newReady(r, prevSoftSt, prevHardSt) 方法中会读取 r.msgs,并设置 n.readyc 通道,后续将 rd 放入 readyc 通道中,等待外部消费;外部通过 node.Ready() 方法获得内部需 apply or 待发送的 Messages
在 etcdserver/raft.go 的 main forloop 中获取 readyc 通道消息 rd := <-r.Ready(),该 apply Messages 放入到 r.applyc 通道,该发送的 r.Messages,调用 r.sendMessages(rd.Messages) 发送,结束之后调用 r.Advance()
另外在 etcdserver/server.go 的 main forloop 中获取 ap ap := <-s.r.apply(),将这次 apply 放入 FIFO 中,FIFO 内部协程异步处理 apply job